

This post originally appeared on IBM Integration Community
As adoption of AsyncAPI increases, a frequent topic of conversation in the community is how to describe publish and subscribe semantics - both now and in future versions of the specification.
In this blog post I aim to introduce the discussion and set you on the right path to document your event driven APIs.
Or in other words, what code would you expect to be generated for the publish operation in the following AsyncAPI document?
1 asyncapi: 2.0.0
2 info:
3 title: My Application
4 version: 1.0
5 servers:
6 bootstrap:
7 url: mybroker.com:3514
8 protocol: kafka
9 channels:
10 myChannel:
11 publish:
12 message:
13 payload:
14 type: stringIf you would be surprised to hear that this would result in a Kafka Consumer, then you should keep reading!

In the beginning
AsyncAPI started as an adaptation of OpenAPI - which describes synchronous request/response based APIs. In an OpenAPI world, you describe the application from the perspective of the client. Or in other words, the OpenAPI document describes how a client should interact with your application. The client and server communicate directly with each other.
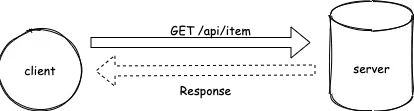
You document that a GET endpoint exists to access data, a POST endpoint exists to create data, etc. In all cases, a client speaks to the application (server) that is serving these endpoints.
If you were implementing an application to honour the contract described in an OpenAPI document, you know to build route handlers that provide the documented endpoints for clients to access.
Callbacks and webhooks are asynchronous operations, but in OpenAPI they are still described from the perspective of the client – the client has to initiate/register with the server before the server will push data to the client.
What about AsyncAPI?
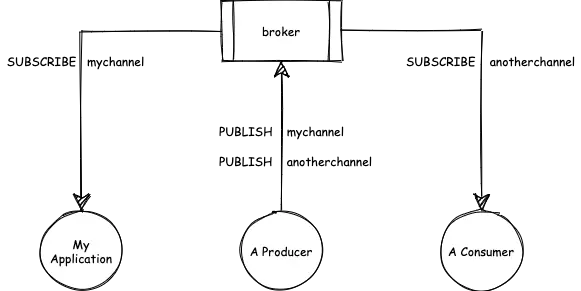
In an event driven architecture there is no client/server paradigm. Applications do not directly communicate with one another - instead, each application sends and receives events via communication channels provided by s messaging infrastructure such as a broker. The broker ensures that events sent to a channel are delivered to interested applications. It can be considered fire and forget - an application sends an event, but does not have any interest in whether other applications receive or make use of the event.
AsyncAPI approaches this by describing an application as having two potential roles:
- If it sends messages to a channel, it's a “Publisher".
- If it is interested in receiving messages from a channel, it is a “Subscriber".
An application can have either one or both roles.
What does the following AsyncAPI document describe?
1 asyncapi: 2.0.0
2 info:
3 title: My Application
4 version: 1.0
5 servers:
6 bootstrap:
7 url: mybroker.com:3514
8 protocol: kafka
9 channels:
10 myChannel:
11 publish:
12 message:
13 payload:
14 type: stringIs My Application a Publisher or a Subscriber?
Answer... it's a Subscriber!
Like with OpenAPI, an AsyncAPI documents an application from the client perspective. For a client to interact with My Application, it must publish an event to the myChannel channel on the Kafka broker hosted at mybroker.com:3514
The exception to the rule is websockets - there is a client/server paradigm rather than a messaging infrastructure - so other applications will connect directly to the server. However, the semantics remain the same - you describe the server as an application from the client perspective. See Lukasz's previous article for more details.
Where's the confusion?
An AsyncAPI document can have multiple purposes. It can act as documentation for other developers to understand how to interact with the API. It can also act as documentation for developers to implement the API.
In OpenAPI, there is no ambiguity - if you implement the API your server must listen for incoming requests on the documented endpoints, and any clients know to make requests to the documented endpoints. A GET endpoint means the same thing to both client and server.
In AsyncAPI, the confusion has arisen because applications can both publish and subscribe - so verbs become interchangeable depending on the perspective of the person reading the document.
When describing your architecture - a collection of applications communicating via channels - it can feel more familiar to describe what each application is doing (it publishes event x to channel a and subscribes to events from channel b).
Conversely, if you are intending on socialising your asynchronous API for use by other developers - it is a more familiar paradigm to describe how external developers can interact with the API. Ultimately, that was the decision for v2.0.0 of the AsyncAPI specification.
What does this mean for using the spec?
The AsyncAPI generator project is designed to facilitate generation of various assets from an AsyncAPI document - including sample or mock applications. The application generators are primarily written to interpret the API as detailed in this blog post - so a publish will generate a Kafka consumer. However, some of the templates have added support for interpreting the document so that a publish generates a Kafka producer.
- Java Spring Cloud Stream template uses the parameter
view=provider- (providerinterprets the AsyncAPI document as describing the behaviours the application provides) - Java Spring template use the parameter
inverseOperations=true
Summary
AsyncAPI documents describe applications. When reading an AsyncAPI document:
publishmeans publish an event to the channel and this application will receive itsubscribemeans subscribe to this channel to receive events published by this application
There is a GitHub issue raised for discussing these semantics moving forward into the next version of the AsyncAPI specification - please do get involved with the discussion!